

Intro
One of the best definitions of an “information system” with a practical approach rather than an academic approach is – an automated system that produces data results for further usage. An algorithm (as an engine for any information system) is a rule to transform input data to output data. So fundamentally any information system is transforming input data to output data. We can even say that’s the sole reason for an information system to exist; therefore the value of an information system is defined through the value of the data. So any information system design starts with data and implements algorithms, hardware and everything else required to deliver data with known structure and value.
Prerequisites
Stored data
We start the design of an information system with data. First of all, we document all planned datasets for processing and storing. Data characteristics include:
- the amount of data
- data lifecycle (amount of new data per period, data lifetime, rules of processing outdated (dead) data)
- data classification with relationship to core business from availability / integrity / confidentiality perspective including financial KPIs (like the financial impact from data lost over the last hour)
- data processing geography (the physical location of data processing hardware)
- external requirements for each data class (personal data laws, PCI DSS, HIPAA, SOX, medical data laws, etc).
Information systems
Data is not only stored, but also processed (transformed) by information systems. So the next step is to create a full inventory of all information systems, their architectural traits, interoperability and relationship, hardware requirements in abstract resources:
- Computing power
- RAM amount
- Storage system space and performance
- Network / interconnect requirements
Ideally, each microservice should have these values defined and documented. Also, again we should emphasize the importance of defining the cost for each service / information influence as it relates to the core business in “$ / hour” for both downtime and data-loss.
Threat model
The next must-have thing is a defined and documented threat model. We cannot design protection against a threat that isn’t documented. Everything else is just a waste of time and resources. A threat model should include all the aspects of availability, integrity and confidentiality, including but not limited to:
- Physical server outages
- Top-of-the-rack switch outages
- Inter-DC network link outages
- Storage system outages
- Etc.
In certain cases several formal threat models should either exist or be created, not just for the information system itself, but also for several other components (the corruption of a logical DB for example). Any threats not documented in the solution design are not relevant.
Regulatory agency requirements
If an information system processes specialized data sets that fall into one or several classes defined by regulators, such as personal or medical data, all of these specific classes must be defined and documented before starting to design.
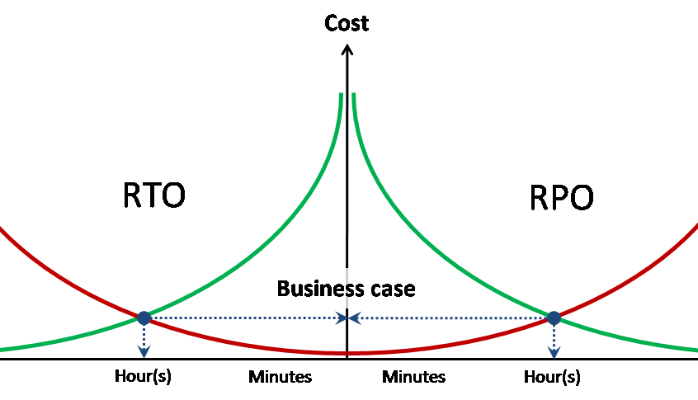
RPO / RTO
Each protection solution design starts with the definition and documentation of objectives for both the recovery duration and the point in time to which we want to recover. As we see, there is a balance for the cost associated with data protection cost and the impact of the loss of data or a service outage. This is why we need to establish the $/hour before designing the solution.
Sizing and design considerations
Resource pools
Once we have finished gathering the necessary inputs for our design, we can finally start with the definition of resource pools. We combine all information systems into a resource pool or split these up because of threat model(s) or regulatory requirements. Resource pools can be physically detached or soft detached (based on a hypervisor or system software). We can also create semi-detached pools, like compute nodes physically detached, but using the same storage system.
Compute power

Abstract compute power requirements for virtualized data centers are measured in the number of vCPUs as well as the consolidation ratio of vCPU:pCPU. In this guide, we treat pCPU as a physical CPU core without counting Hyper-Threading. We add up all required resource pool vCPUs from the overall requirements. Remember that each resource pool can have its own consolidation ratio.
Consolidation ratios for big workloads or mission-critical system can only be determined empirically by putting such system into a virtualized pool and measuring, or by re-using values from a previous installation. Systems that do not have a high load or are not considered mission critical can use ratios defined in best practices. For example 1:5 for general purpose mixed server workload and 8-10:1 for VDI.
RAM
We calculate RAM requirements by simple addition. We strongly suggest to avoid any form of memory oversubscription unless you know what you’re doing, but you’d probably write sizing guides instead of reading them 🙂
Storage
Storage requirements we calculate adding up the numbers as well, for both space and performance.
We’d like to remind you that generally speaking storage performance is measured in IOPS (input-output operations per second) and not in MBps (megabytes per second) unless you’re designing media streaming or video surveillance storage. So gather all IOPS, and if possible include things like average read/write ratio, latency requirements, and the block sizes of storage operations.
Data network
Data network requirements are also usually summarized as the amount of bandwidth that is required. In some cases, we also specify QoS (quality of service) requirements including RTT (round trip time) for particular services or systems.
Also, we should specify any relevant network security requirements such as isolation, encryption and particular implementation specifics such as 802.1q, IPSec, RoCE, and so on.
Architecture choice
We exclusively use the x86 architecture in this guide, and we aim for a 100% virtualized solution. Naturally, the architectural choice is then split up between different virtualization platforms, the server form factor and server configurations.
An essential choice is to define if we are going with a classic approach where we choose the individual tiers for compute, storage and data networking or if we target a converged solution.
A classic architecture uses external intelligent storage and networking subsystems while servers merely provide compute power and RAM. As an extreme case, servers become stateless with no boot disks and even no system id. In this case, the servers boot from the external storage system (boot from SAN/NAS) or network (PXE). In most cases however a server boots into an operating system designed for virtualization (a hypervisor) from its local disks or flash device.
For the last 10+ years, we’ve seen blade servers as a very popular choice, but frequently this choice was made without any practical approach. So, what principles should we use to determine if we should go rack or blades?
- Economics (in general rack servers are a little bit cheaper);
- Compute density (blade servers have an advantage);
- Power consumption and heat (blades increase density);
- Scalablity and ease of use in big infrastructures (blades are simpler to manage);
- Extension cards (blades only offer a limited amount of options).
Converged architecture (also known as hyperconverged) means that we combine compute and storage subsystems, sometimes networking as well. With a converged architecture there is no need for intelligent external data storage systems, as we leverage software-defined, scaled out storage with the use of local disks.
The “hyperconverged” term was introduced to make a distinction between truly converged architecture products and “converged systems”, the former containing traditional systems with separate compute, storage and networking. Marketing teams used the “converged” term to show that the whole system with a single part number contained compute, storage and networking, but not in the architectural meaning.
Calculations
CPU / Memory
We need to understand workload type for each of independent physical cluster to be able to make right sizing.
CPU bound – environment where CPU load is close to 100% and no additional RAM would allow to place more workload while maintaining performance.
Memory bound – environment with memory load close to 100%, while CPU is not. So additonal RAM meand additional workload or overall performance.
GB / MHz (GB / pCPU) – average ratio for each particular workload for RAM and CPU. We can use this ratio to calculate RAM required for defined performance and vice versa.
Server configuration

First of all we define all workloads (resource pools) and decide whether we combine workloads on single cluster or split into multiple clusters. Next step: we determine GB / MHz ratio for each cluster, or we use vCPU:pCPU ratios to translate overall resource pool requirements into physical silicon.
pCPUsum = vCPUsum / vCPU:pCPU – overall number of physical cores we need.
pCPUht = pCPUsum / HT – number of cores we need with HyperThreading enabled. We can see a lot of different opinions on how much HT is improving performance, but authors assume 25% would be safe enough number for mixed workloads with lots of small VMs. So HT = 1.25 in this case.
Let’s assume we need to size the cluster for 190 cores / 3.5 TB RAM. We also assume target load levels 50% CPU and 75% RAM. We do separate calculation for CPU and RAM.
| pCPU | 190 | CPU util | 50% | ||
| Mem | 3500 | Mem util | 75% | ||
| Socket | Core | Srv / CPU | Srv Mem | Srv / Mem | |
| 2 | 6 | 25,3 | 128 | 36,5 | |
| 2 | 8 | 19,0 | 192 | 24,3 | |
| 2 | 10 | 15,2 | 256 | 18,2 | |
| 2 | 14 | 10,9 | 384 | 12,2 | |
| 2 | 18 | 8,4 | 512 | 9,1 |
In this case we always use roundup to next integer, so 25.3 becomes 26 (=ROUNDUP(A1;0)) as we physically cannot install 0.3 servers.
Next we match number of servers we need for target workload with particular CPU model and particular amount of RAM. As we see there are three balanced server configurations:
— 26 servers 2*6c / 192 GB
— 19 servers 2*10c / 256 GB
— 10 servers 2*18c / 512 GB
Further choice could be made with additional factors: rack space available, power consumption, server configuration standards or software licensing.
Of course this is not a calculation that include every detail, we even skip base CPU frequency in this example, but it should give you the overall direction on how to. Each particular case and sizing can be very different.
Some additional things to consider on server config
Wide VMs
Highly loaded systems usually takes one or more wide VMs (VM size is more than 1 NUMA node). So preferable choice for hosting wide VMs would be if they become “narrow” and fit into 1 node. For example VM requires 16 vCPUs and 160 GB of RAM. That means that 2-ways servers with less than 16 cores per CPU and less than 384GB would be a bad choice. If there are a lot of wide VMs we also should consider resource fragmentation and choose configs that allow to fit wide VMs tightly.
Fault domain size
Other thing to consider while making a choice is fault domain size. For example there are 2 options:
— 3 x 4*10c / 512 GB
— 6 x 2*10c / 256 GB
If there is no additional requirements second option is preferred. If server goes into maintenance or down we lose only 17% of resources instead of 33%. There is also twice as much impact for HA event – twice more VMs will restart on first config means more impact on business logic and systems.
Classic storage systems sizing

Classic storage systems should be sized for worst case and should not include cache or optimization logic into sizing if we don’t want to be embarassed before the business unit. Base performance for mechanical disks (IOPSdisk):
— 7.2k – 75 IOPS
— 10k – 125 IOPS
— 15k – 175 IOPS
Then we calculate disks need to achieve required performance:
= TotalIOPS * ( RW + (1 –RW) * RAIDPen) / IOPSdisk
— TotalIOPS – required overall performance
— RW – read ops percentage
— RAIDpen – RAID penalty for RAID level selected (2 for RAID10 or RAID0, 4 for RAID5, 6 for RAID6)
After that we use vendors best practice to determine number of hot spares, number of disk groups etc. We’d like to emphasize: this is how non-tirered storage system is sized. Once you add SSDs in any way – things change a little.
Tricks with Flash cache
Flash Cache – common name for all proprietary technologies using flash memory as second level cache. As a general rule mechanical disks sizing is used for serving steady workload while flash cache to compensate peaks. Also be advised that different vendors use flash cache very differently and you should always read best practice by storage system vendor.
If we want to use flash cache wisely, then we should remember that cache is only for workload with high access localization and gives very little for evenly loaded volumes (like analytics systems).
Hybrid low-end / mid-range systems
Low-end and mid range storage systems implement tiered storage with scheduled data movement. In average they also have pretty big storage block for tiering size of 256 or even more megabytes, because it is resource consuming technology and you have to have a lot of CPU and RAM on service processors (storage controllers) to maintain all the access tables and heat maps. This consideration does not allow us to take vendors word and use this kind of tiered storage as performance improving technology. Tiered storage on mid-range and low-end systems is cost saving technology for workload with uneven load.
Tiered storage sizing considers only the highest tier as performance, while low tier is calculated only capacity-wise. We should always use flash cache together with tiering to compensate performance degradation for hot data that hasn’t been moved to performance tier yet.
SSD usage in tiered storage

Way to use SSD as tier heavily depends in particular flash cache implementation for each vendor.
General SSD usage policy for tiered storage — SSD first.
Read Only Flash Cache. SSD tier for such systems is only needed when there is significant writes localization.
Read / Write Flash Cache. First of all we need to max out flash cache as it works small blocksize in realtime instead of scheduled large block for tiers, and only then we introduce SSD tier.
We would like to remind once again: sizing is always made according to vendors best practice and for worst case scenario.
Special thanks to Bas Raayman.